
Al recolectar los datos, de una sola variable, lo primero es pensar como lo vamos a ordenar y a clasificar, nos centramos, en la forma de visualizar una distribución, ella depende de si la variable de interés es categórica o numérica, es decir, si la variable es cualitativa, cuantitativa discreta o cuantitativa continua.
Variables categóricas o cualitativas y sus distribuciones.
Las variables categóricas toman solo unos pocos valores específicos. Por ejemplo, el género es una variable categórica común, quizás con las categorías "masculino", "femenino" y "no conforme con el género".
Para visualizar la distribución de una variable categórica, usamos lo que se llama un gráfico de barras, estos muestran cuántos elementos se cuentan en cada conjunto de categorías. Por ejemplo, el siguiente gráfico de barras se realizó con la finalidad de ver gráficamente cuantos estudiantes o alumnos realizan cursos en la academia fz .

Es una variable cualitativa nominal, donde se cuenta cuántas personas hay en cada curso de programación.

Es una variable cualitativa nominal, donde se cuenta cuántas personas hay en cada curso de programación.
Debido a su naturaleza discreta, no hay mucho que decidir al dibujar un gráfico de barras. Un analista puede elegir el orden de las categorías, el color de las barras y la relación de aspecto, para visualizar dicho información.
Variables numéricas (Cuantitativas Discreta o Continua) y sus distribuciones.
Las variables numéricas se miden como números. La altura es numérica, a menudo se mide en centímetros o pulgadas. La edad es numérica, medida en años o días. Las variables numéricas pueden ser discretas o continuas . Las variables discretas solo toman valores enteros (1, 2, 3, etc.). Las variables continuas toman cualquier valor a lo largo de la línea numérica o el conjunto de números reales (1.7, 14.06, etc.).
Cuando una variable es numérica, su distribución se puede representar de varias maneras ; Probablemente el método más común es el histograma.
Justin Wolfers de The Upshot produjo el histograma de la siguiente figura para visualizar los tiempos finales de 10 millones de corredores de una maratón.
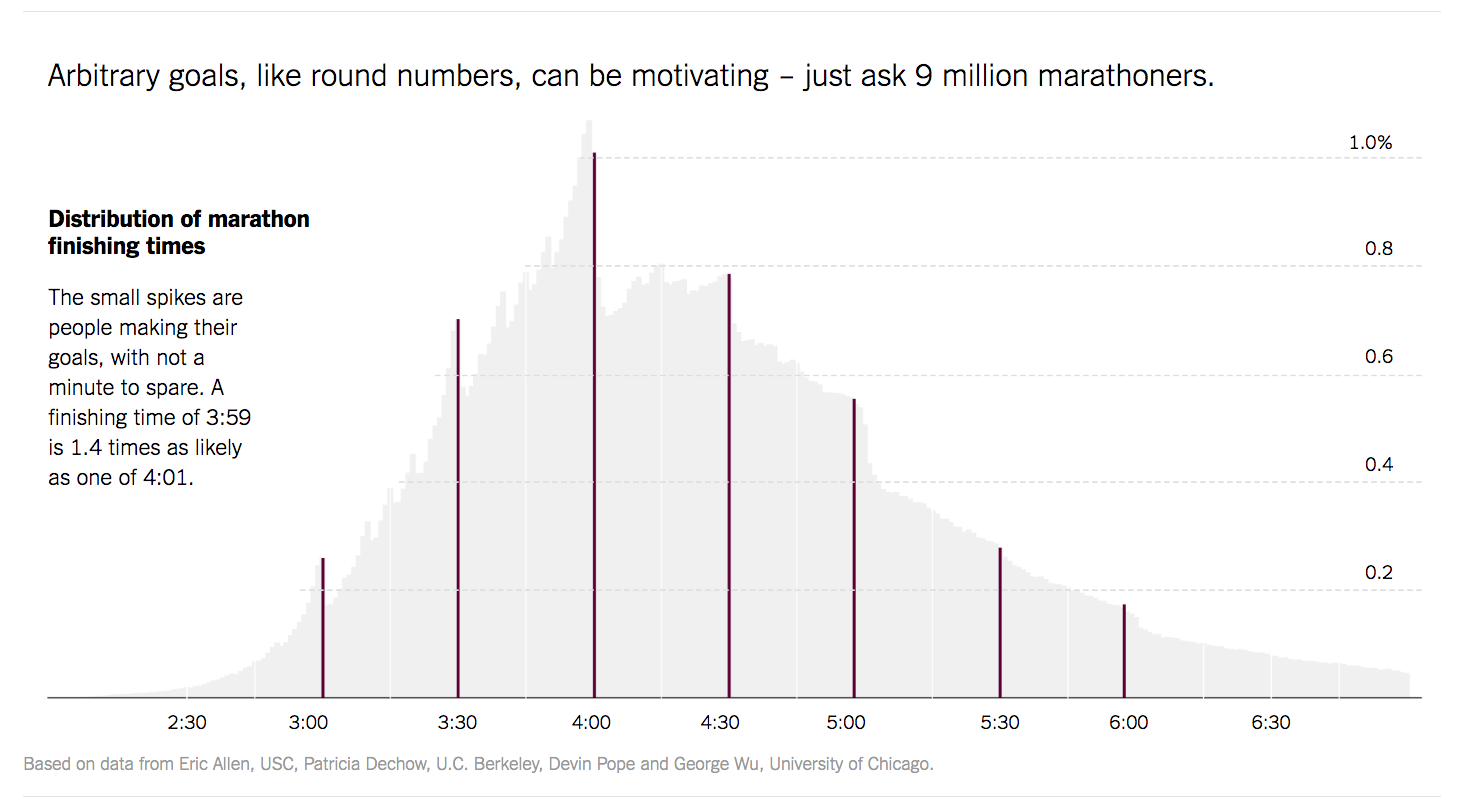
A primera vista, la creación de un histograma parece bastante simple: dividimos los datos en un conjunto de contenedores, cajas o grupos, discretos, luego contamos cuántos valores caen en cada uno de los grupos. Pero, al observar más detenidamente, vemos que en realidad hay muchas opciones que se deben tomar para crear un histograma que represente fielmente la forma de la distribución.
Cómo construir un histograma
Reúne tus datos
Un histograma se basa en una recopilación de datos sobre una variable numérica. Nuestro primer paso es reunir algunos valores para esa variable. Podemos visualizar el conjunto de datos como un conjunto de elementos, con cada elemento identificado por su valor, que en teoría nos permite "ver" todos los elementos, pero hace que sea difícil obtener un comportamiento de la variable. ¿Cuáles son algunos valores comunes? ¿Hay mucha variación?
Ordenar en una lista
Un primer paso útil para describir la distribución de la variable es ordenar los elementos en una lista. Ahora podemos ver el valor máximo y el valor mínimo. Más allá de eso, es difícil decir mucho sobre el centro, la forma y la distribución de la distribución. Parte del problema es que la lista está completamente llena; el espacio entre dos elementos es el mismo, sin importar cuán diferentes sean sus valores. Necesitamos una forma de ver cómo los elementos se relacionan entre sí. ¿Están agrupados alrededor de unos pocos valores específicos? ¿Hay un objeto solitario con un valor muy alejado de todos los demás?
Construye la Distribución de Frecuencias
Obtén el Rango, ======>>>>> Rango = Valor Mayor - Valor Menor, esto es para determinar el intervalo total, donde estarán comprendidos todos los valores de la serie de datos a estudiar.
Luego tienes que decidir el número de intervalos de clases a realizar, no hay reglas para esta decisión, todos los métodos existentes son empíricos, según las bibliografias de Estadísticas mas famosas en el tema. Se recomienda hacer distribuciones de frecuencias que tengan mínimo cuatro (4) intervalos de clases, máximo siete (7), ya que su visualización es aceptada en la mayoría de los casos. Los intervalos de clases deben ser, siempre que sea posible, iguales, a fin de de que la comparabilidad entre las frecuencias de las diversas clases se torne fácil. El intervalo de clase no debe ser tan grande que oculte las características más importantes de la variable a estudiar.
luego de obtener el Rango y el Número de Intervalos. se realiza el cálculo del Tamaño de cada Intervalo o intervalo de Clases.
Rango = (VM - Vm) ; NI =Número de Intervalos
Tamaño del Intervalo =Rango/Número de Intervalos
Un procedimiento alternativo para determinar el intervalo de clase o tamaño del intervalo, ha sido sugerido por H.A. Sturges, aplicando la siguiente fórmula:
Tamaño del Intervalo = Rango/( 1+3,322*log(N))
Esta fórmula da valores fraccionarios no adecuados para su uso en la práctica; sin embargo, podemos aplicar las reglas de redondeo y convertirlos en enteros o eliminar algunos decimales en cuanto sea posible.
Es importante indicar con precisión los limites de las clases y evitar clasificaciones como estas:
0--------10
10------20
20------30
Un procedimiento alternativo para determinar el intervalo de clase o tamaño del intervalo, ha sido sugerido por H.A. Sturges, aplicando la siguiente fórmula:
Tamaño del Intervalo = Rango/( 1+3,322*log(N))
Esta fórmula da valores fraccionarios no adecuados para su uso en la práctica; sin embargo, podemos aplicar las reglas de redondeo y convertirlos en enteros o eliminar algunos decimales en cuanto sea posible.
Es importante indicar con precisión los limites de las clases y evitar clasificaciones como estas:
0--------10
10------20
20------30
como se observa los valores 10 y 20 pertenecen a dos clases, los cuales cuando estemos registrando las frecuencias se realizarían dobles. Tampoco se debe escribir:
más de 0 menos de 10
más de 10 menos de 20
ya que el valor de 10 no pertenece a ninguna de las clases citadas.
Una forma de presentación de clases que se sugiere es:
0-----9,9
10---19,9
20---29,9
30---40
la cual no presenta los vicios señalados anteriormente
otra clasificación correcta es para variables discretas
10------19
20------29
30------39
40------49
50------59
Una vez , construidos los intervalos de clases, registramos la frecuencia que tiene los datos de la variable a estudiar, en cada uno de los intervalos de clases, ya una vez obtenida la distribución de frecuencias, se dibuja los ejes de coordenadas sobre el plano
En el eje de las abscisas (x), se coloca los intervalos de clases y sobre el eje de las ordenadas la magnitud de cada frecuencia, luego se levantan rectángulos o barras en cada clase formada.
En el caso del maratón, por ejemplo, el tiempo mínimo fue 2 horas, y el tiempo máximo de los maratonista fue de 5 horas.
Hallamos el rango. Rango = 5-2 = 3
Luego decidimos que el número de intervalos es 6.
Hallamos el Tamaño de cada intervalos es Ic = 3/6 = 1/2 =0.5
Construimos la Distribución de Frecuencias
Distribución de frecuencia
Se escribe la variable Frecuencia
↓ ↓
Tiempo en horas y minutos N° de personas
2,00 ------------------2,5 99
2,501-----------------3,0 201
3,001-----------------3,5 450
3,501-----------------4,0 350
4,001-----------------4,5 188
4,501-----------------5,0 112
Total 1400
Distribución de frecuencia
Se escribe la variable Frecuencia
↓ ↓
Tiempo en horas y minutos N° de personas
2,00 ------------------2,5 99
2,501-----------------3,0 201
3,001-----------------3,5 450
3,501-----------------4,0 350
4,001-----------------4,5 188
4,501-----------------5,0 112
Total 1400
En excel sería así:


La Gráfica o Histograma, del lado del eje de las ordenadas, se levanta la columna del N° de personas, y del lado del eje de las abscisas, se construyen los intervalos de clases, en este caso: las horas del tiempo de la maratón, las cuales fueron agrupadas por cada media hora.
Preguntas : Porqué se seleccionó 6 intervalos de clases?
Cuál es la distribución de los datos?
Los histogramas proporcionan una forma de visualizar datos agregándolos en barras, y se pueden utilizar con datos de cualquier tamaño.
La división de elementos en las barras: la esencia de un histograma
Reunir los datos en barras nos ayuda a responder la pregunta "¿Cómo es la distribución de estos datos?" Imagine, que ud. intenta describir algunos conjuntos de datos, que le están comunicando por teléfono, en lugar de leer mecánicamente toda la lista de valores, sería más útil proporcionar un resumen, como para poder decir, si la distribución de la variable es simétrica, dónde está centrada y si tiene valores extremos, etc. Un histograma es otro tipo de resumen, en el que se comunican las propiedades generales en términos de porciones (es decir, barras) de los datos
Tal vez porque los histogramas son visualmente similares a los gráficos de barras, es fácil pensar que también son objetivos similares. Pero, a diferencia de los gráficos de barras, los histogramas se rigen por que se visualizan las variables cuantitativas continuas, donde un intervalo tiene inmediatamente la secuencia del otro en términos de números reales.Además, podemos señalar que antes de describir un conjunto de datos a alguien, en función de lo que ve en su histograma, debe saber si los diferentes valores de los parámetros podrían haberlo llevado a diferentes descripciones.
Lo importante es que un histograma, es un resumen representativo de un conjunto de datos subyacente.
En la figura del histograma anterior que se puede visualizar? Cual es el comportamiento de la variable? Que podemos decir de los datos? Se observa la data o distribución simétrica? Que conclusiones podemos sacar de la gráfica?
Con este pequeño ejemplo, espero haber ayudado un poco a resolver la construcción del Histograma, si tienes alguna duda, deja tu comentario o escribe al correo zavafree@gmail.com que con gusto trataré de aclarar las dudas.
En la figura del histograma anterior que se puede visualizar? Cual es el comportamiento de la variable? Que podemos decir de los datos? Se observa la data o distribución simétrica? Que conclusiones podemos sacar de la gráfica?
Con este pequeño ejemplo, espero haber ayudado un poco a resolver la construcción del Histograma, si tienes alguna duda, deja tu comentario o escribe al correo zavafree@gmail.com que con gusto trataré de aclarar las dudas.













